Related Research

Geo-bench-2
An evolution of the benchmarking framework that shifts focus from pure performance metrics to capability assessment. Geo-bench-2 provides deeper insights into what geospatial AI models can actually do, moving beyond simple accuracy scores to understand functional capabilities and limitations across diverse Earth observation tasks.
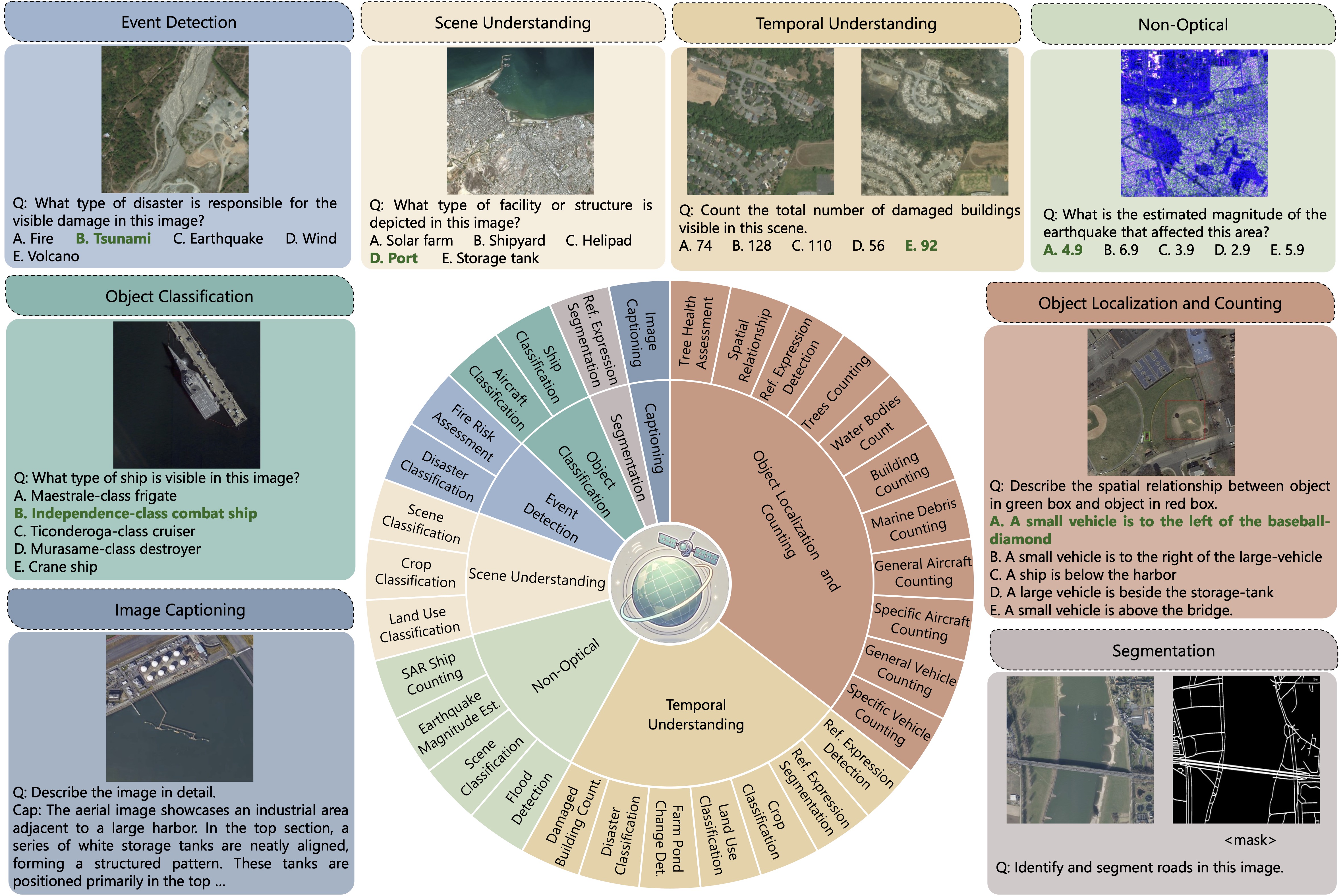
GEOBench-VLM
The foundational benchmark for evaluating vision-language models on geospatial tasks. GEOBench-VLM introduces comprehensive evaluation protocols for temporal analysis, object detection, damage assessment, and spatial reasoning, establishing standards for measuring VLM performance in Earth observation applications.
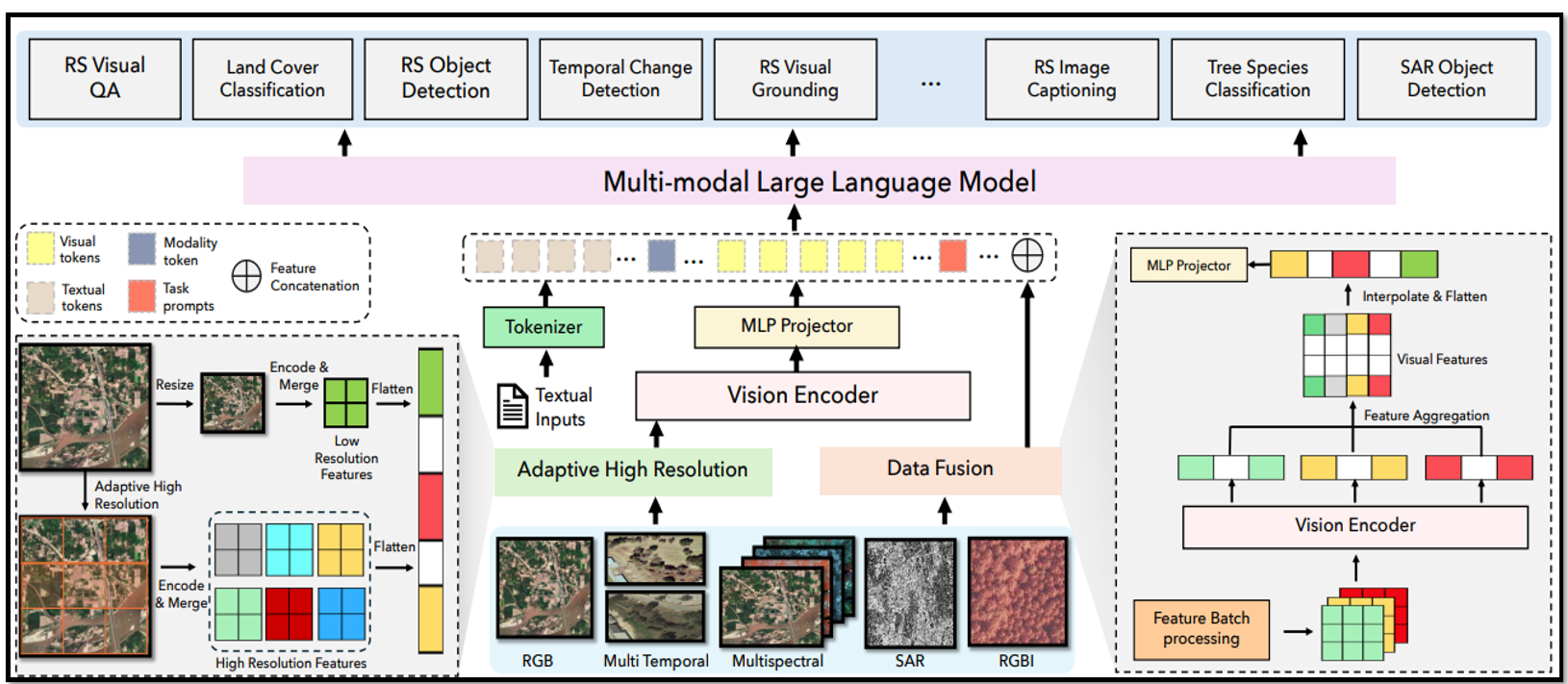
EarthDial
A practical application demonstrating the capabilities measured by GEOBench-VLM. EarthDial transforms multi-sensory Earth observations into interactive dialogues, showcasing how vision-language models can enable natural language interfaces for complex geospatial analysis and decision-making tasks.